Week 04: Filling in some details#
Learning outcomes#
After completing this lesson, you will be able to
customize many aspects of plotnine plots
make 2d plots displaying 3 variables
understand the basics of file paths
prepare your own dataset for an analysis
read your own dataset into Python
Preparation#
To follow along with this Lesson, please open the Colab notebook Week 04 Notes. The first code cell of this notebook calls to the remote computer, on which the notebook is running, and installs the necessary packages. For practice, you are repsonible for importing the necessary packages.
Graphing details#
In this section, we cover some details about customizing a plotnine plot. This lesson will not explore all available options, nor are you expected to memorize all the details we cover. This lesson is intended to be an introduction to the types of things you can easily change on a plotnine plot. For details and/or reference material on computer software, you should consult the plotnine documentation.
Let’s continue developing the plot we started at the end of Week
03. Our goal is to display information about the mean
total amount of sleep mamals (in our dataset) get, where the data are
grouped by the categorical variable vore. This is a task for
aggregating: group by vore and summarize sleep_total with the
function np.mean. Since the mean of any dataset is random, as part
of the random sampling of the data, we should also calculate and
display the error in our estimate associated with the mean. That is,
we should display a confidence interval for the mean.
import numpy as np
import pandas as pd
import plotnine as pn
from plotnine.data import msleep
After loading the appropriate Python packages, we aggregate our dataset: group
by vore and calculate means, by groups, of the numeric variable sleep_total.
Since vore has some missing data, we’ll drop rows of the DataFrame where
vore is missing.
df = msleep.dropna(subset = "vore")
odf = (df
.groupby("vore", as_index = False)
.aggregate(
mean = ("sleep_total", np.mean),
sd = ("sleep_total", np.std),
count = ("sleep_total", np.size)))
/tmp/ipykernel_2061/944327102.py:3: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
/tmp/ipykernel_2061/944327102.py:3: FutureWarning: The provided callable <function mean at 0x7f3364fe9790> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
/tmp/ipykernel_2061/944327102.py:3: FutureWarning: The provided callable <function std at 0x7f3364fe98b0> is currently using SeriesGroupBy.std. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "std" instead.
Next, we’ll calculate confidence intervals, to visualize our uncertainty in the mean estimates given the fact that we only have a sample (subset) of the vores. In fact, let’s calculate two confidence intervals, a wider interval with a greater level of confidence for which we will capture the true mean of all vores, and a narrower interval with a (relatively) smaller level of confidence that we will capture the true mean.
odf["se"] = odf["sd"] / np.sqrt(odf["count"])
# 95% confidence
odf["ub2"] = odf["mean"] + 1.96 * odf["se"]
odf["lb2"] = odf["mean"] - 1.96 * odf["se"]
# 68% confidence
odf["ub1"] = odf["mean"] + odf["se"]
odf["lb1"] = odf["mean"] - odf["se"]
In the upcoming plot, we’ll also plot the categorical (non-numeric)
variable Vore on a numeric-continuous scale. To help us do that,
let’s create a new column in both DataFrames df and odf that holds
unique numeric values for each level of Vore.
df["numeric_vore"] = df["vore"].cat.codes
odf["numeric_vore"] = odf["vore"].cat.codes
/tmp/ipykernel_2061/766632350.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
Since plotnine plots are created by adding layers of information, let’s get
started by creating the variable p to hold our plot as we build it up piece by
piece. Below is an alternative version of the code we used from Week 03.
p = (pn.ggplot(data = odf)
+ pn.geom_point(pn.aes(x = "numeric_vore", y = "mean"),
color = "blue", shape = "X", size = 2.5))
The keyword arguments color and shape, when they appear inside a
geom_ layer and outside of aes, take just one color and one shape.
Because plotnine is built on top of other Python packages, matplotlib
specifically, finding the available colors and shapes can be tricky.
Here are links to the matplotlib named colors and the matplotlib available shapes.
p.draw()
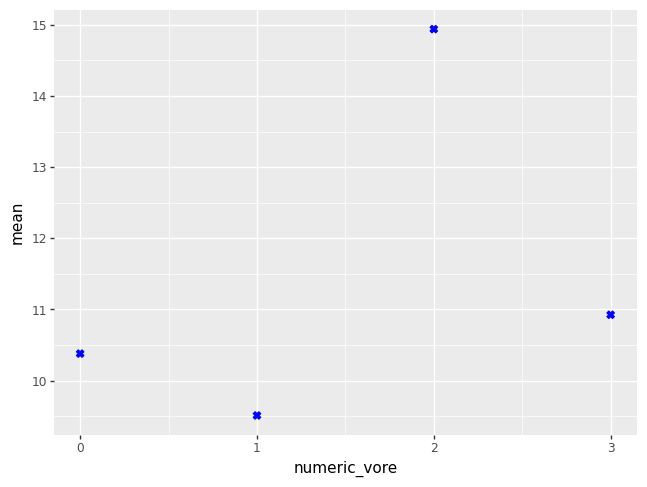
So far, we used “X”s for the mean of each group. No confidence intervals, no group names (just numbers representing their group names), no original data, and no plot title. And maybe we want to change the axis labels. Let’s take each of these in turn. We leave it to the reader to display the plot after each update, if they so choose. We’ll show the complete plot only at the end of all of our updates.
Let’s add the confidence intervals, using the geom_linerange layer.
p += pn.geom_linerange(pn.aes(x = "numeric_vore", ymin = "lb2", ymax = "ub2")) # 95%
p += pn.geom_linerange(pn.aes(x = "numeric_vore", ymin = "lb1", ymax = "ub1"), size = 1.5) # 68%
The syntax p += expression is equivalent to p = p + expression. It
certainly takes some time to get used to, but it is also very convenient. For all
of the layers we are interested in adding on to our plot p, we just want to
update p to hold the latest version of our plot. There is no sense in keeping
around the previous version of our plot. So this syntax is just what we want.
Next, let’s add the original data. Putting the original data on a plot is increasingly popular and always recommended. It helps you and your reader understand the variation in your data, and will often help explain why one (or more) groups may appear different.
p += pn.geom_jitter(df, # notice the change in dataset
pn.aes(x = "numeric_vore", y = "sleep_total", color = "vore"),
width = 0.25, # the maximal width of horizontal noise/jitter
alpha = 0.5
)
The layer geom_jitter is like geom_point but adds a bit of
horizontal noise/jitter in the x-axis. Since the x-axis of this plot
is vore status, and not actually numbers, adding horizontal noise
doesn’t change the information in the data at all. For clarity, we
want to prevent overlap of data between the levels of vore, so
choosing the right value for the keyword argument width takes some
care.
By specifying a categorical variable for the keyword argument color within
aes, the jittered points will show up in unique colors for each category of
the variable specified, vore in this case. Further, a legend will
automatically be displayed. Changing the category names of the variable vore is
best done by renaming the categories, as in Week 02: Categorical
variables, but we can easily change the
legend title from plotnine.
p += pn.guides(color = pn.guide_legend(title = "Vore status"))
To remind your readers, and future-you, that the x-axis here is a categorical variable, let’s change the tick labels to better represent what information they actually contain.
p += pn.scale_x_continuous( # continuous x-axis scale based on numeric codes of vore
breaks = df["numeric_vore"].to_list(), # breaks dictate where on the x-axis, a list of numeric values
labels = df["vore"].to_list() # list of labels at breaks
)
Next, let’s change the axis labels and title.
p += pn.labs(
x = "Vore status", y = "Sleep (hours)",
title = "Hours of sleep by vore status"
)
Last, let’s change the plot theme and font size, just to show that you can. Actually, I much prefer simpler themes, so as to highlight the data instead of the plot.
p += pn.theme_minimal(base_size = 12)
p.draw()
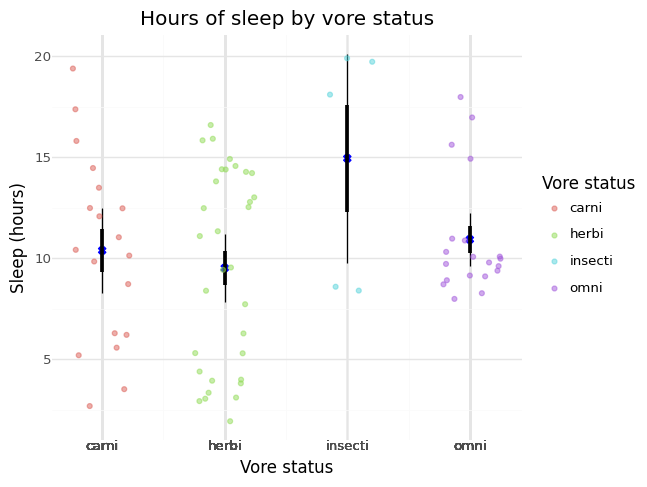
Some final thoughts on the plot above. I’d prefer the means not be
blue. The default black would probably be better, but then I wouldn’t
have been able to tell you more about the keyword argument color.
The units of your variables show up in your plots, to inform you reader, but do now show up in your variable names.
The categories for vore should be changed. Using abbreviations in
your writing and/or plots is usually not helpful to anyone but you.
There are ways to change the categories through plotnine, instead of
by changing your DataFrame. I don’t recommend this. There’s little
to no reason to use abbreviations for label names in your original
data; refer to Week 02: Categorical variables.
Some people would have reached for geom_errorbar before geom_linerange. The
difference is a pair of horizontal lines on the top and bottom of the confidence
intervals. I see the appeal of this, but prefer the minimalism of
geom_linerange.
For a hot minute, people were debating whether or not standard deviations or standard errors were better, when drawing lines extending from a mean as we have done here. The correct answer is it depends. If you want to talk about means across groups, then use standard errors. If you want to talk about population distributions across groups, then your data should at least be roughly symmetric, and then use standard deviations.
Your own data#
In this section, we’ll learn about where/how files, such as a dataset, are stored on your computer and how to properly enter data into a spreadsheet for later data analyses. We begin with understanding file paths. File paths are not Python specific. A file path is like the URL of a specific file on your computer. Each file on your computer has an address and that address is called a file path.
So far we’ve relied on a dataset that already exists on your machine. The main reason behind this is that file paths can be confusing at first. And so we’ve delayed this topic until near the end. Invariably, though, you will need to load your own dataset.
directories#
All computers organize their files in directories, which are sometimes called folders. Think of a directory as a specific drawer in which logically grouped files go.
Whenever you login to a computer, you should imagine that you are immediately
(as if standing) within one of the many directories of that machine. Whichever
directory you are currently in is called the current working directory.
Sometimes the current working directory is abbreviated cwd or even just
wd. The current working directory is written ..
From the current working directory, you can move up or down the directory hierachry. Which is to say directories can contain other directories, and chances are good the current working directory is located within another directory. The root of the directory tree is called the root directory.
Each user on a computer has their own directory, which is a (not necessarily immediate) child of the root directory. Such a directory, unique to each user of a computer, is called their home directory.
Every file and every folder on a computer has exactly one parent
directory. The parent directory is spelled ...
visualizing directory structure#
There are many different ways to visualize directory structure. On a
Mac, the application Finder, and on Windows machines File Explorer,
both help users navigate files and directory structure. A more
traditional way to visualize directory structure is with the command
tree.
From a Colab notebook, one can access the remote computer, on which the notebook
is running, by prepending an appropriate command with !, commonly called bang. The
command pwd prints the current working directory. The command tree prints
the directory structure below its one argument, a file path.
For instance, the command tree ., where . represents the current working
directory, will print the contents of the current working directory all the way
down to the children files contained within any and all sub-directories.
tree indents sub-directories and contained files relative to their parent
directory. In addition to indents, tree makes use of vertical and
horizontal lines to help your eye better visualize where the directory
boundaries are.
file paths#
Every directory on a computer is referenced by a file path (an
address). Directories are separated by a forward slash /, as is
each file name. Imagine a dataset named bike.csv contained in a
series of directories math131 and data. Such a file would have
file path ./math131/data/bike.csv. This file path tells us that we
are in a directory ., which contains a directory named math131.
The directory math131 itself contains a directory named data, and
the directory data contains a file named bike.csv. We will learn
about the file extension .csv in the next sub-section.
File paths that begin with . (current working directory) or ..
(parent of the current working directory) are called relative file
paths. Such file paths are relative to the current working
directory. File paths that begin with the root directory are called
absolute file paths. For the most part, we will encourage use of
relative file paths.
delimited files#
We next look at the ways in which most small to medium sized datasets are organized. Large datasets should use a database and databases are beyond this course. Consider the following table of data.
type |
size |
color |
|---|---|---|
trouser |
6 |
black |
dress |
8 |
blue |
sneaker |
7 |
silver |
ankle boot |
8 |
brown |
coat |
44 |
green |
sandal |
9 |
black |
A table of data is often called tabular data. Tabular data are organized in rows and columns. Each row is an observation, or separate unit of analysis, and each column is a variable. Variable names show up in the first, or zero-th row, and the data are in all subsequent rows.
Such a dataset is often stored in a delimited file. Within a row,
a delimited file separates, or delimits, each variable’s value with a
special character. The most common delimiters are comma ,, or some
amount of white space, a single space or a fixed number of
spaces,, or a tab spelled \t and often written as visually
equivalent to two, four, or eight spaces. Each has its own faults. The
world has mostly settled on comma separated values, hence .csv file
extensions.
Comma separated values would list in a text file the row for trouser
as trouser,6,black. A file of tabular data such as this would have
file extention .csv, which helps quickly identify the type of file.
In a .csv file, the entire table of data above would look as follows.
type,size,color
trouser,6,black
dress,8,blue
sneaker,7,silver
ankle boot,8,brown
coat,44,green
sandal,9,black
There are some simple problems with csv files. Imagine a dataset that contains
as values sentences, specifically sentences which possibly contain commas.
Here’s an example: For instance, this sentence.. To avoid the comma within a
variable’s value being conflated with a delimiting comma, people have started
surrounding individual variable values with double quotes. Double quotes is not
the only choice, but it is the common choice for a quote character.
Now imagine a dataset that contains as values strings with double quotes in
them. There’s solutions to this problem, too: escape characters. The most
common espace character is a back slash \.
As you can see, in extreme cases csv files are challenging to get
right. So are tab delimited files, .tsv, for similar reasons. We
generally rely on spreadsheet software and mature programming packages,
like the Python package Pandas, to simplify our lives for writing and
reading delimited files.
The Python package Pandas function named read_csv should be used to read in
your own data. The function read_csv defaults to a comma as delimiter, double
quotes as quote character, and back slash \ as an escape character. It is
thus your job to get your data into a csv file appropriately. The easiest
solution is to type your data into a spreadsheet and then export your
spreadsheet data into csv format.
read in your own data#
This whole section is prep-work. Once you understand file paths and have entered your data into a delimeted file structure (.csv, .tsv, or otherwise), the Python package Pandas makes reading in the data relatively simple. The code below is an example of reading in a .csv file into a DataFrame, just as we worked with beginning in Week 01: Dataframes.
df = pd.read_csv("./path/to/your/data.csv")
your data in a Google Colab notebook#
When dealing with your own data while working in a Google Colab notebook, you have to remember that the computer on which your notebook runs is not the computer in front of you. This means, to read data into Python, you need to upload any dataset onto the Colab notebook computer.
To upload a dataset to the notebook computer, click on the folder looking icon, folder, near the top left of the Colab notebook within your browser. Confusingly, the tooltip you get when hovering over the folder icon reads Files. Then click the upload file icon, upload_file, to upload the dataset you want.
Let’s say the file you uploaded is named research_data.csv. If
upload your dataset into the current working directory on the notebook
computer, then the file path will be ./research_data.csv, and the
code to read this file into Python, using Pandas, is
df = pd.read_csv("./research_data.csv")
If, before uploading your dataset, you created a new directory named
data, and then you uploaded research_data.csv into the directory
data, the file path will be ./data/research_data.csv, and the code
to read this file into Python, using Pandas, is
df = pd.read_csv("./data/research_data.csv")
See also